Filebeatsからの入力とローカルのファイルを読み込んでの処理を分けるためにマルチパイプラインの設定をする。
 |
| 公式サイト(Introducing Multiple Pipelines in Logstash)より |
https://www.elastic.co/blog/logstash-multiple-pipelines
https://www.elastic.co/guide/en/logstash/master/multiple-pipelines.html
以前作成したFilebeatsの設定ファイルを転用して, CSVファイル用の設定ファイルを作成して, それぞれ異なるパイプラインで処理する設定を行う。
CSVファイルで使うのは長年エクセルで管理してグラフ化していた光熱費のデータを使う(笑)。
手順
1. /etc/logstash/pipelines.yml 作成
2. filebeatsのConfig(既存転用)とCSV用のConfigを作成
3. index Pattern作成
4. グラフ作成
1. pipelines.yml 作成
pipelines.ymlには各パイプラインの設定を記述する。ここに記述されなかった設定はlogstash.ymlを参照してそれに従うとのこと。
・pipelines.yml には個別設定
・logstash.yml には共通設定
という住み分けらしい。(多分)
vi /etc/logstash/pipelines.yml
# For beats
- pipeline.id: filebeat
pipeline.workers: 2
pipeline.batch.size: 125
pipeline.batch.delay: 5
config.reload.automatic: true
config.reload.interval: 5s
path.config: "/etc/logstash/pipeconf.d/beats.conf"
# For csv
- pipeline.id: csvfile
pipeline.workers: 1
pipeline.batch.size: 125
pipeline.batch.delay: 5
config.reload.automatic: true
config.reload.interval: 5s
path.config: "/etc/logstash/pipeconf.d/csv.conf"
これに伴って /etc/logstash/logstash.yml を以下のように変更した。
vi /etc/logstash/logstash.yml
path.data: /var/lib/logstash
log.level: info
path.logs: /var/log/logstash
最低限のものに絞ったので設定値はpipelines.ymlへ持っていった。
2. csv用設定ファイル作成
csvファイルは次のような要素になっている。
「YYYYM,電気代,水道代,ガス代」
実際のデータはこんな感じ。
「201712,9308,11765,10018」
input {
file {
path => "/tmp/logstash/kounetsu.csv"
start_position => "beginning"
}
}
filter {
csv {
columns => ["date", "elec", "water", "gus"]
skip_empty_columns => true
convert => {
"elec" => "integer"
"water" => "integer"
"gus" => "integer"
}
}
date {
match => [ "date", "yyyyM"]
}
}
output {
elasticsearch {
hosts => [ "http://172.16.10.50:9200" ]
index => "kounetsu"
}
}
3. index pattern作成
elasticsearchへ”kounetsu”というインデックスで渡しているので kibana でこれを指定してインデックスパターンを作成する。
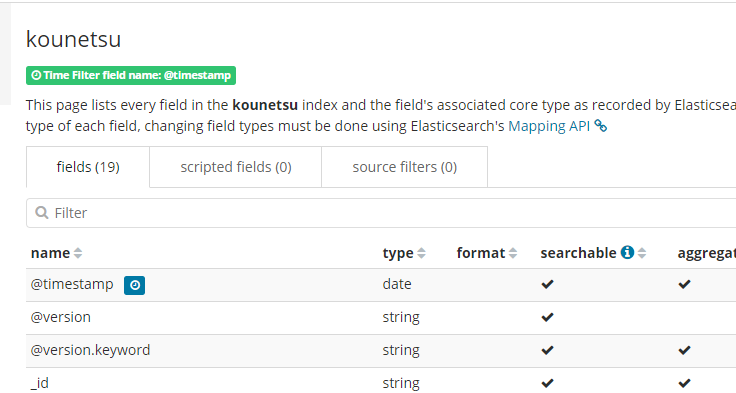
4. グラフ作成
ここはお好みでとなりますが。。。
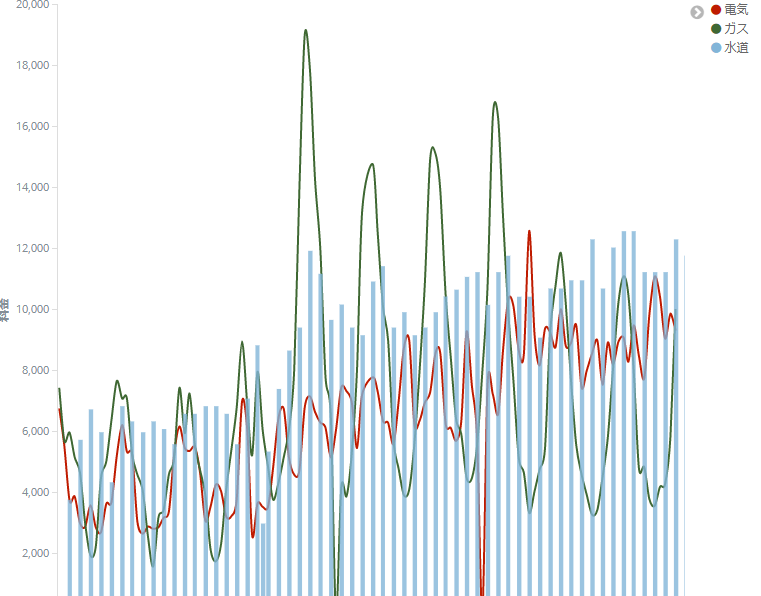
完成。
できるまで結構ハマっていたのでこれをポチった。 無駄にはならないよね・・・。
