RDO(All-in-One)アップグレード(Queens→Yoga)
そろそろOpenStackの環境を更新しようと。 こことここにならってコンポーネント毎にアップグレードを行っていく。 オフィシャルでは始める前にsytemdのスナップショットをとれとあるが,そんなオプションはないと怒られ… 続きを読む »
そろそろOpenStackの環境を更新しようと。 こことここにならってコンポーネント毎にアップグレードを行っていく。 オフィシャルでは始める前にsytemdのスナップショットをとれとあるが,そんなオプションはないと怒られ… 続きを読む »
想定構成 以下構成で10GbpsのNICを2本束ねる。 参考URL nmcli を使用したネットワークチーミングの設定 チーミングインタフェースを作成 物理IFをチーミングに所属 チーミングIFを有効化 teaming… 続きを読む »
cronの書き方で毎度悩む期間指定。めったに触らないから調べても忘れる。 ということでメモ。 基本的な記述は,「分,時,日,月,曜日」の5つのフィールドに指定したい値を書く。 毎時,毎月などは スラッシュで指定する。例え… 続きを読む »
とある検証でL3SWでGREトンネルのみ張る設定を確認した。普通にいけるかなと思ったが,keepaliveでひっかかったのでメモ。 基本的には,Vlan IFにIPアドレスを設定し,tunnel source / des… 続きを読む »
先日,Microsoftのオンラインセミナー受講したらバウチャーを配布してくれたので受験してきました。Azureの初級という位置づけで,「クラウド初めてさわる」「これからAzure案件に関わる予定」という人向けのようです… 続きを読む »
Bloggerを使っていたけれど,使い勝手がよいWiki形式へ切り替えたいと思い,勉強がてらWordpressを自前で立ててこちらへ引っ越し。 1発目はWordpress構築メモ。 構想 構成イメージはこのような感じ。G… 続きを読む »
IOS準備 TFTP立ち上げ コンソール接続 既存OS削除 再起動 rommonで起動 setコマンドで IP_ADDR / NETMASK / DEFAULT_ROUTER を設定 tar -xtract tftp:/… 続きを読む »
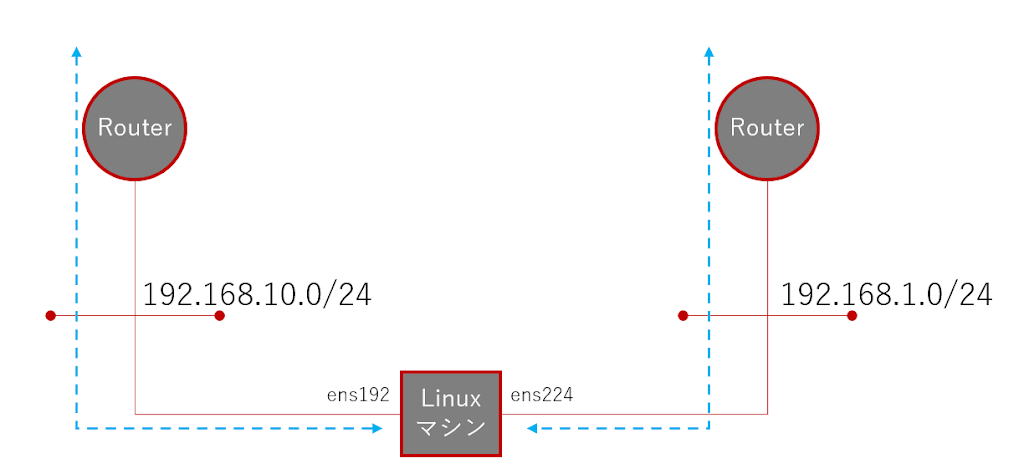
AWSでインスタンスを立ち上げたとき,2つのサブネットに所属させ一方は社内ネットワーク,一方はメンテナンス用に外部(インターネット)からSSHアクセス用にと構成することがある。 この場合,それぞれのNICに着信したトラフ… 続きを読む »
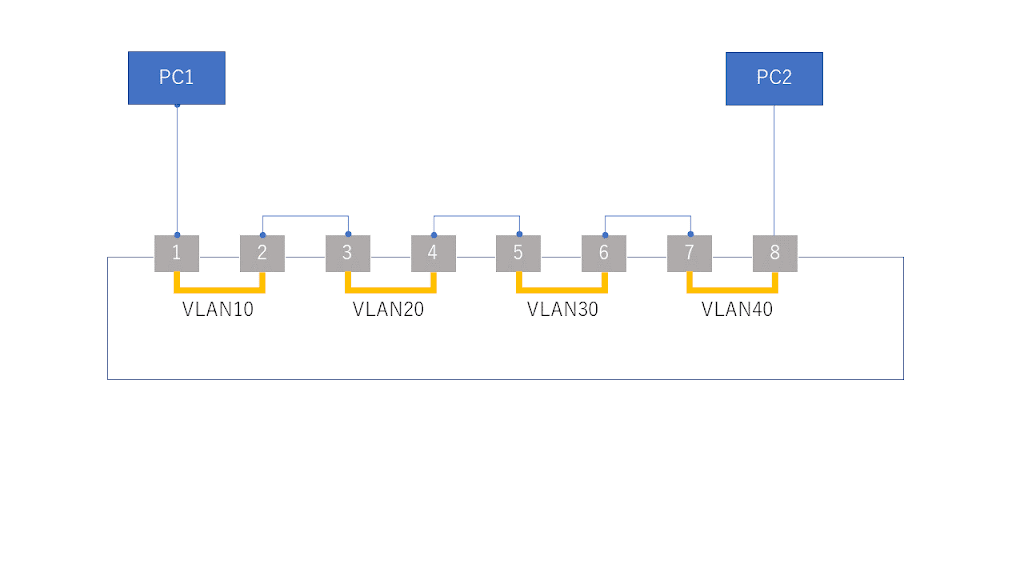
欲しかった10Gのスイッチを米アマ経由で調達した。 環境準備や設定・スループット測定などいろいろと手間取ったのでメモ。 購入したのMikroTik CRS309。米アマで購入当時およそ$270。輸送費やもろもろ税がかかっ… 続きを読む »

背景 昨今の在宅の流れにより家のメインPCが夫婦で取り合いになる状況が多くなってきた。それを受けて,新しくPCを新調することにした。せっかくなのでゲームもできるPCにしようと小型ながらもゲームに耐えうるものを自作した。 … 続きを読む »